

Agents Become Workflow Infrastructure
Executive Summary
The strongest AI discourse signal today was not a single model claim but a convergence in how agents are being packaged: as managed workflow infrastructure with isolation, permissions, source discipline, and platform-level placement. The practical question is shifting from “can an agent do the task?” to “where should the agent run, what context should it see, how is its work audited, and when should the human intervene?”
What Happened
Microsoft’s Liam Hampton used an AI Engineer talk, “Cooking with Agents in VS Code”, to frame VS Code as a control plane for agent work rather than just another chat surface. His taxonomy is useful: local agents for hands-on iteration and tests, background/worktree agents for larger implementation tasks, and cloud agents for lower-touch repo hygiene or documentation. The important admission was also the sober one: agents are not one-shot magic workers. They need task decomposition, permission boundaries, token awareness, and workflow context.
On the infrastructure side, Onur Solmaz’s “Scaling Agents on Kubernetes with acpx and ACP” made the same argument from another layer. MCP gives tools to models; ACP, in his framing, standardizes agent-to-client interaction. The proposed enterprise shape is disposable, on-demand agents running in isolated Kubernetes pods, dispatched from Slack, Discord, or web UIs, each with a full environment for a specific task. That is a long way from “chatbot in the sidebar.” It is closer to a workflow engine for bounded automation.
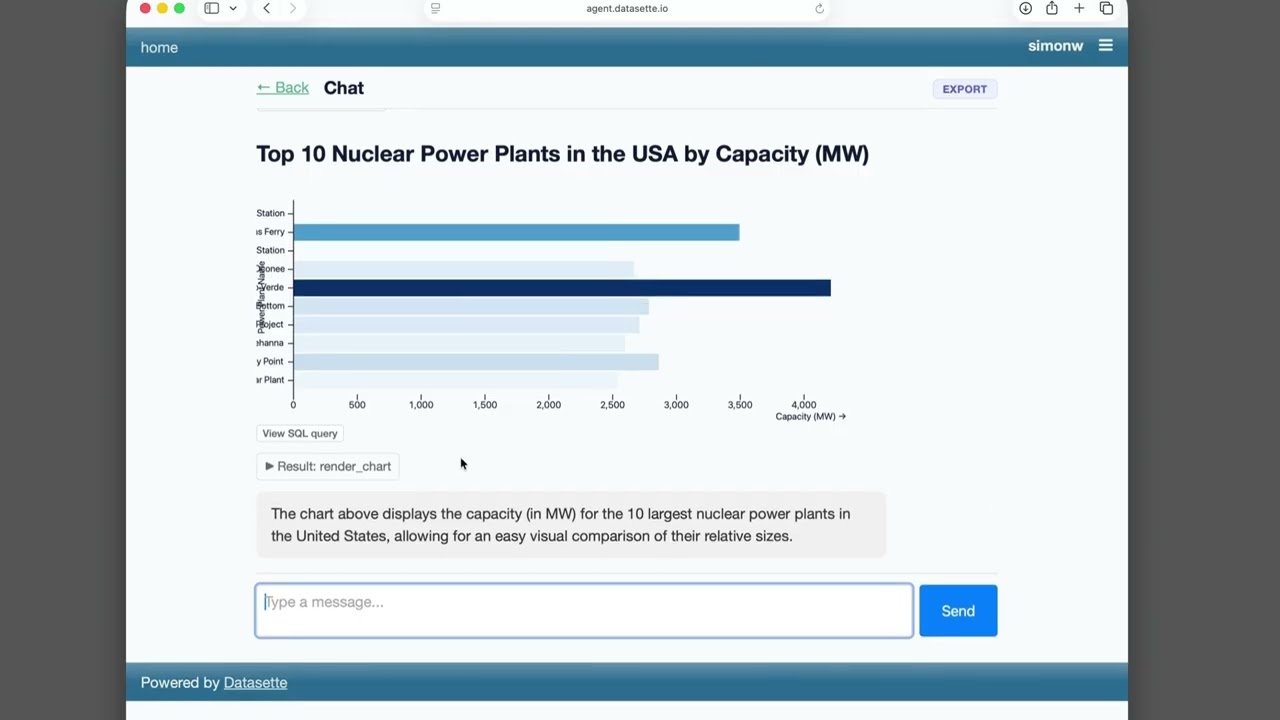
Simon Willison’s Datasette Agent release put the pattern into product form. Datasette now has an extensible assistant for querying structured data, built around his LLM library, with chart generation delegated to a plugin. A companion sandbox-execution plugin reinforces the important implementation detail: useful agents are becoming compositions of data access, tools, plugins, and sandboxes, not merely larger prompt boxes.
Google’s Android AI Q&A with Florina Muntenescu and Oli Gaymond, “AI on Android: Ask me Anything”, added the platform version of the same story. Google framed Android AI development as three paths: on-device inference via ML Kit GenAI/Gemini Nano, hybrid fallback via Firebase AI Logic, or cloud inference through Gemini/Vertex providers. AI Core is the key abstraction: one shared system-level on-device model with hardware optimization, request isolation, no local storage of app inputs/outputs, scheduling, and foreground priority. The agentic future on mobile looks less like every app shipping its own model and more like operating systems mediating local model access.
Why It Matters
This reinforces the digest’s developing view that agent adoption is mainly an orchestration problem. The visible progress is not just model quality; it is where models sit inside work. The durable pattern is: isolate execution, constrain context, expose costs, preserve artifacts, and let humans review the right intermediate states.
Nate B Jones’s “Your AI Writes From Twenty Sources. It Cannot Tell Which One Is Wrong.” supplied the human-workflow counterpart. His core claim was that serious hallucination failures are increasingly structural: agents synthesize from stale, contradictory, or unauthoritative source sets, then produce polished documents with hidden weak spots. His mitigation is not “write a better prompt,” but build a bounded project room before drafting: preserve originals, inventory files, judge authority and currentness, summarize sources, surface conflicts, identify missing context, and only then synthesize.
That maps directly onto the tooling pattern above. Whether the surface is VS Code, Kubernetes, Datasette, Android, or a research workspace, the winning agent pattern is not autonomy in the abstract. It is disciplined context construction plus inspectable execution.
The Bigger Story
There was also a trust-and-hype edge to the day. Simon Willison linked the FTC settlement over Cox Media Group and others allegedly deceiving customers about an “Active Listening” AI-powered marketing service. This was not the main technical story, but it matters as a boundary marker: vague AI claims around surveillance, targeting, and inferred intent are meeting regulatory scrutiny.
Rich Holmes’s feed item on Google Search generating UI on demand pointed in the same product-directional area, though the available evidence was only the summary. If search, mobile OSes, IDEs, and data tools all become dynamic AI-mediated surfaces, product expectations will change quickly. But the credible part of that transition is not “AI everywhere.” It is AI embedded where the platform can manage permissions, context, latency, cost, and fallback behavior.
Workflow Implications
For operators, the practical lesson is straightforward: do not evaluate agents only by final-output quality. Evaluate the scaffolding around them. Good systems will make source sets visible, isolate risky execution, separate local/background/cloud tasks, expose usage, preserve intermediate reasoning artifacts where appropriate, and give humans clear review points.
The day’s discourse was therefore less about a new capability threshold than a maturity threshold. Agents are becoming real when they stop pretending to be autonomous coworkers and start behaving like auditable workflow infrastructure.
Further Reading
- How Physics Can Teach Neural Nets to Discover Hidden Biology — a useful explainer on constrained models and scientific discovery workflows, especially the idea that structured failure can be more informative than black-box fit.