

Agent Ops Is Becoming an Infrastructure Problem
Executive Summary
The clearest signal today was that serious AI practice is moving away from “which model is best?” and toward “what boundary, policy, and evaluation regime makes this safe and economical to run?” Two AI Engineer talks made the point from different angles: one reframed agent sandboxes around network identity and secret minimization; the other argued that state of the art is a Pareto frontier of quality, speed, cost, and energy, not a leaderboard trophy. Supporting signals from account-recovery failure, product-team routines, and benchmark commentary all point in the same direction: the agent era is forcing operators to treat AI capability as governed infrastructure, not just smarter software.
What Happened
The strongest concrete item was Remy Guercio’s AI Engineer talk, “What if the network was the sandbox?”. The argument is simple but important: an agent sandbox is not only a VM, container, or isolated runtime. It is a boundary plus permissions. If credentials, OAuth sessions, and provider API keys live inside that boundary, then the sandbox still contains the very authority an attacker or misbehaving agent wants.
The proposed alternative is to move more of the authorization surface to the network layer. In the Tailscale framing, an agent, CI runner, or review bot can connect with a short-lived network identity; policy can be applied at a gateway; and provider keys need not be placed inside the agent environment at all. Their Aperture gateway example keeps model-provider credentials at the gateway, applies model/provider/cost policy based on identity, and creates a control point for logging requests, responses, tool calls, bash commands surfaced through model-provider streams, per-agent cost, and webhook events.
That matters because it changes the sandbox conversation from “where does the process run?” to “where does authority live?” As agents gain tool access, the practical security question is less whether a box is isolated in the abstract and more whether the agent can exfiltrate the credentials, impersonate a user, or bypass the policy plane.
The day’s other main item, Bertrand Charpentier’s AI Engineer talk, “20 days of compute vs 7 hours: rethinking what state-of-the-art means”, attacked the same operational blind spot from the model-selection side. His claim: there are multiple “state of the art” models, because leaderboards disagree and aggregate scores hide task-specific behavior. A model that wins one benchmark may not be best for object removal, background editing, text editing, or a particular production workflow.
The economic example was the sharper point. A quality-only selection can push teams toward large, slow foundation models even when a faster model gets acceptable results for the actual use case. In the talk’s example, evaluating 26,000 images with a slow model takes roughly 20 days of compute and about $5,000, while a faster performance model can run the same scale in about seven hours and about $265. The recommended pattern is not anti-benchmarking; it is better benchmarking: many samples, user-use-case conditions, multiple benchmarks, efficiency metrics, and Pareto fronts instead of one universal winner.
Why It Matters
Together, these two talks make a useful correction to current AI discourse. Agents are often discussed as a capability story: better models, longer context, more tool use, more autonomy. Today’s stronger evidence says the more durable story is systems design. Model capability only becomes useful when paired with evaluation, identity, policy, observability, and cost controls.
That also clarifies why some smaller signals from the day fit without needing to carry the report. Simon Willison flagged reporting on a Meta AI support flow in which attackers allegedly persuaded an AI support bot to link high-profile Instagram accounts to attacker-controlled email addresses: “Hackers Simply Asked Meta AI to Give Them Access to High-Profile Instagram Accounts. It Worked”. The available evidence here is excerpt-level, so it should not be over-described. But the lesson is consistent: when an AI surface touches account recovery, the critical failure is not merely a bad answer. It is misplaced authority.
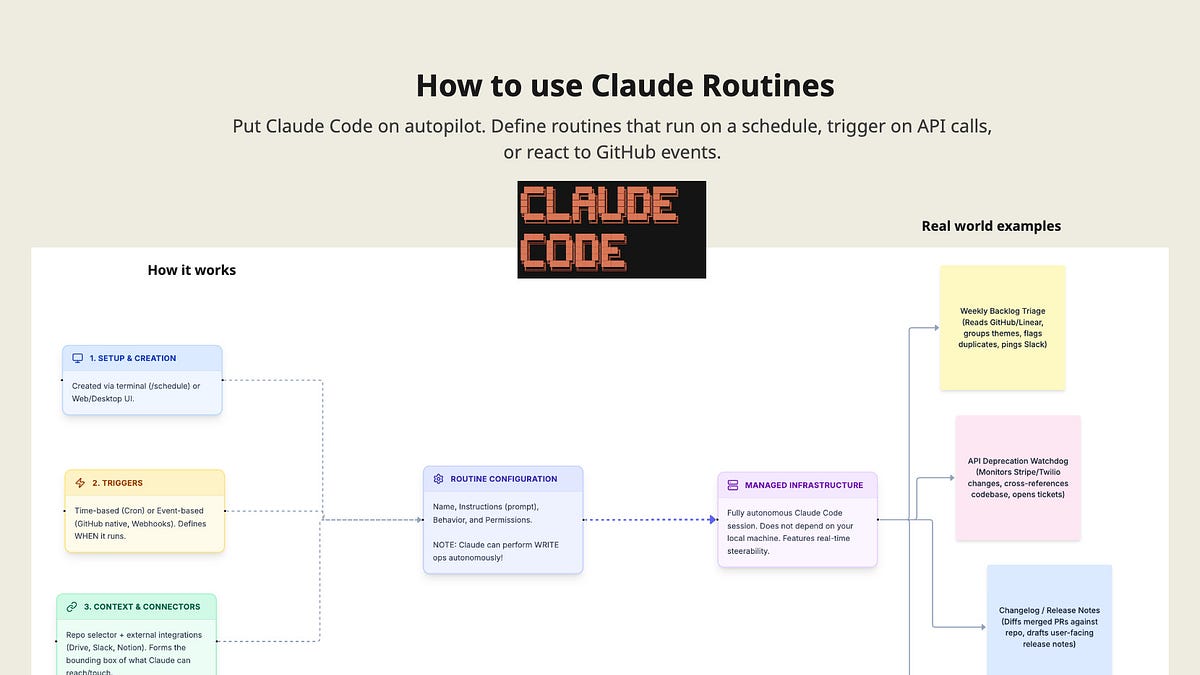
Rich Holmes’ guide to Claude Routines for product teams was also only available at snippet level, but the listed examples — backlog triage, API deprecation monitoring, user-feedback aggregation — show where workplace AI discourse is heading. The use cases are recurring operational loops, not one-off chats. Once AI is embedded in recurring loops, the questions become: what triggers it, what data can it see, what action can it take, who reviews it, and how do we know it worked?
The Bigger Story
This reinforces a developing canon: the frontier is not just model progress; it is operationalization under constraint. The most credible builders are less interested in declaring a universal winner and more interested in composing systems that can be measured, bounded, and audited.
There was secondary discourse around Anthropic financial disclosure, ARC-AGI-style reasoning tests, and contamination-resistant software-engineering benchmarks in Wes Roth’s “GPT-5.6 about to DROP”. The title-level GPT rumors remain unconfirmed and are not the story. The useful thread is that both investors and engineers are asking for harder evidence: balance sheets for AI economics, original tasks for benchmark validity, and qualitative inspection of what kind of reasoning a test forces.
Workflow Implications
For operators, the recommendation is straightforward: stop treating model choice, agent security, and workflow automation as separate decisions. Pick models against the actual task frontier; keep secrets outside agent runtimes where possible; route agent traffic through enforceable policy points; and review AI-generated work with people who have enough context to catch errors at the right abstraction level.
Further Reading
- What if the network was the sandbox? — Remy Guercio, Tailscale
- 20 days of compute vs 7 hours: rethinking what state-of-the-art means — Bertrand Charpentier, Pruna
- Hackers Simply Asked Meta AI to Give Them Access to High-Profile Instagram Accounts. It Worked — Simon Willison
- Practical ways to use Claude Routines at work — Rich Holmes