


AI Agents Hit the Delivery Bottleneck
Executive Summary
The strongest signal today was not a new model release but a clearer theory of why coding agents are powerful without being straightforward labor replacements. The emerging consensus is that AI is compressing the execution layer of software work, while the durable bottlenecks remain deciding what should be built, verifying what was delivered, and carrying accountability for the result.
That matters because it reframes two otherwise contradictory stories: on one side, companies and builders can point to dramatic automation inside narrow workflows; on the other, the evidence for immediate mass displacement remains weak. The useful question is no longer “can AI write code?” It is “which parts of the delivery system have actually stopped needing human judgment?”
What Happened
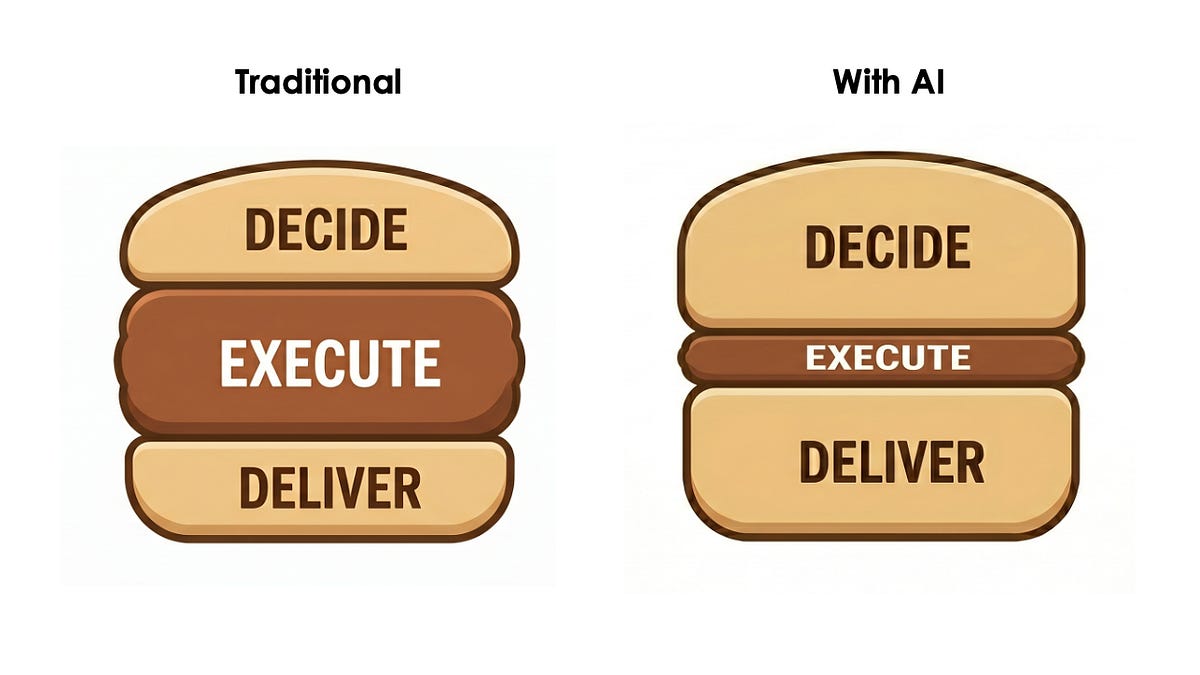
Arvind Narayanan and Sayash Kapoor’s essay, amplified by Simon Willison, offered the cleanest frame of the day: software engineering is a “decide-execute-deliver sandwich.” AI compresses the middle layer — implementation — but leaves much of the work around specification, verification, integration, maintenance, and organizational accountability intact. Their strongest claim is deliberately anti-deterministic: even in software engineering, a field with unusually high AI exposure and relatively few regulatory barriers, the available evidence is enough to reject the simple story that crossing a model-capability threshold mechanically produces mass layoffs.
The essay’s most useful move is to separate “AI wrote a lot of code” from “AI shipped the product.” Those are different metrics. A tool can increase code volume dramatically while releases, integration, quality control, and responsibility remain constrained by human and organizational bottlenecks. Narayanan and Kapoor cite the need for qualitative understanding of the codebase, the business, and the environment as the hard-to-automate substrate beneath both deciding and delivering. Willison adds a practitioner’s caveat: AI can help with deciding and verifying too, but deep human understanding is still the source of much of the value.
A same-day product example sharpened the point from the opposite direction. Department of Product highlighted Coinbase’s internal design-to-code agent, described as converting Figma designs into production-ready code and reducing a feature workflow from roughly 16 days to 4. Even if taken as a company-specific case rather than a universal benchmark, the pattern fits the sandwich model: the biggest gains come when a bounded handoff is well specified, repetitive enough to automate, and close enough to existing engineering constraints that humans can review the result.
Why It Matters
The displacement debate often treats software engineering as the leading indicator for all knowledge work: if coding falls, everything else follows. Today’s evidence complicates that. Software is unusually exposed to AI because the work product is textual, testable, and already mediated by tools. If even there the bottlenecks have shifted rather than disappeared, then broader claims about automatic white-collar replacement need more than model demos or percentages of AI-written output.
This does not make the labor story benign. The same model can be true while individual careers become more volatile, teams shrink in some functions, junior pathways change, and companies raise expectations for output. But the mechanism looks less like instant substitution and more like workflow recomposition: execution gets cheaper, so the scarce work moves toward problem framing, taste, integration, domain context, review, and ownership.
The Bigger Story
Jack Clark’s Import AI added a second piece of supporting context from the evaluation side. Cognition’s FrontierCode benchmark is designed to test whether models can handle production-relevant coding tasks, and Clark notes that Claude Opus 4.8 scores 13.4% on the hardest “Diamond” tier. The exact benchmark will need time to prove itself, but the directional message is useful: serious builders are still trying to measure whether agents can perform under realistic repository constraints, not just produce plausible snippets.
That reinforces the developing canon: agents are becoming real workflow actors, but the frontier is increasingly about reliability under context, not raw generation. A high-performing assistant that needs expert framing, supervision, and review is still a major productivity tool. It is not the same thing as an accountable engineer, product owner, or delivery organization.
Workflow Implications
For operators, the practical takeaway is to instrument the whole delivery loop. Track not just code generated, prompts run, or tasks attempted, but time-to-merged-change, escaped defects, review load, rollback rate, requirement churn, and who remains accountable when the system is wrong. The teams that benefit most from agents will likely be those that make the decide and deliver layers explicit enough for AI to assist without pretending those layers have vanished.
Further Reading
- Arvind Narayanan and Sayash Kapoor, “Why AI hasn’t replaced software engineers, and won’t” — the central argument for the decide-execute-deliver model: https://www.normaltech.ai/p/why-ai-hasnt-replaced-software-engineers
- Simon Willison’s link/commentary on the essay — a concise practitioner bridge to the same argument: https://simonwillison.net/2026/Jun/14/why-ai-hasnt-replaced-software-engineers/
- Jack Clark, Import AI 461 — useful context on FrontierCode and the push toward more realistic coding-agent evaluation: https://jack-clark.net/2026/06/15/import-ai-461-alignment-is-not-on-track-frontiercode-and-synthetic-research-interns/